
Consecuencias de una especificación errónea
Consideraremos algunos ejemplos que nos permitirán demostrar las consecuencias de una especificación incorrecta en el contexto del modelo de regresión lineal.
En este post estaremos utilizando los siguientes paquetes de R:
# Instalar paquetes si es necesario
# install.packages("margins")
# install.packages(ggplot2)
# install.packages(dplyr)
# install.packages(lmtest)
# Leer paquetes
library(margins)## Warning: package 'margins' was built under R version 4.0.2library(ggplot2)
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(lmtest)## Warning: package 'lmtest' was built under R version 4.0.2## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numericSimulación Monte Carlo
Supongamos que el modelo correcto es:
\[ y_i = \beta_1 + \beta_2 x_i + \beta_3 x_i^2 + \beta_4 z_i + \beta_5 z_i^2 + u_i. \] Sin embargo, sin darnos cuenta de nuestro error, estimamos el modelo: \[ y_i = \beta_1 + \beta_2 x_i + \beta_3 z_i + u_i. \] ¿Cuáles son las consecuencias?
Para responder a esta pregunta, haremos una simulación Monte Carlo suponiendo que el proceso generador de datos es:
\[ \begin{aligned} \beta_1&=1000 \\ \beta_2&=-2\\ \beta_3&=0.3 \\ \beta_4&=-2\\ \beta_5&=0.3\\ x &= 2 + 6* \mathcal{U}(0,1)\\ z &= 2 + 6* \mathcal{B}(2,4)\\ u &= 3* \mathcal{N}(0,1),\\ \end{aligned} \] donde \(\mathcal{U}\), \(\mathcal{B}\) y \(\mathcal{N}\) se refiere a las distribuciones uniforme, beta y normal, respectivamente.
El siguiente código hace todos los cálculos necesarios. Hemos elegido crear \(n=10000\) valores artificiales para las variables involucradas y repetir el experimento 500 veces.
### Initialize parameters
nobs <- 10000
sims <- 500
AMEx.t = matrix(0,nrow=sims,ncol=1)
AMEz.t = matrix(0,nrow=sims,ncol=1)
AMEx.e = matrix(0,nrow=sims,ncol=1)
AMEz.e = matrix(0,nrow=sims,ncol=1)
AMEx.st = matrix(0,nrow=sims,ncol=1)
AMEx.se = matrix(0,nrow=sims,ncol=1)
beta_1=1000
beta_2=-2
beta_3=0.3
beta_4=-2
beta_5=0.3
### Run simulations
indx <-1
while(indx < sims){
x <- 2 + 6*runif(nobs, min=0, max=1)
z <- 2 + 6*rbeta(nobs, shape1=2,shape2=4)
u <- 3*rnorm(nobs,0,1)
y <- beta_1 + beta_2*x + beta_3*x^2 + beta_4*z + beta_5*z^2 + u
### MCO estimations
mod.t <- lm(y~x+I(x^2)+z+I(z^2))
mod.e <- lm(y~x+z)
AMEx.t[indx]<-summary(margins(mod.t))[1,2]
AMEz.t[indx]<-summary(margins(mod.t))[2,2]
AMEx.e[indx]<-summary(margins(mod.e))[1,2]
AMEz.e[indx]<-summary(margins(mod.e))[2,2]
AMEx.st[indx] <- as.double(summary(margins(mod.t, at=list(x=6), variables="x"))[3])
AMEx.se[indx] <- as.double(summary(margins(mod.e, at=list(x=6), variables="x"))[3])
indx <- indx + 1
}Para visualizar los resultados, comparamos la distribución del efecto marginal promedio con especificación correcta y con especificación incorrecta. En esta, podemos ver que el efecto marginal promedio de \(x\) sobre \(y\) es consistente aun cuando el modelo no está bien especificado. Esto se debe a que la distribición de \(x\) que hemos elegido es simétrica.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.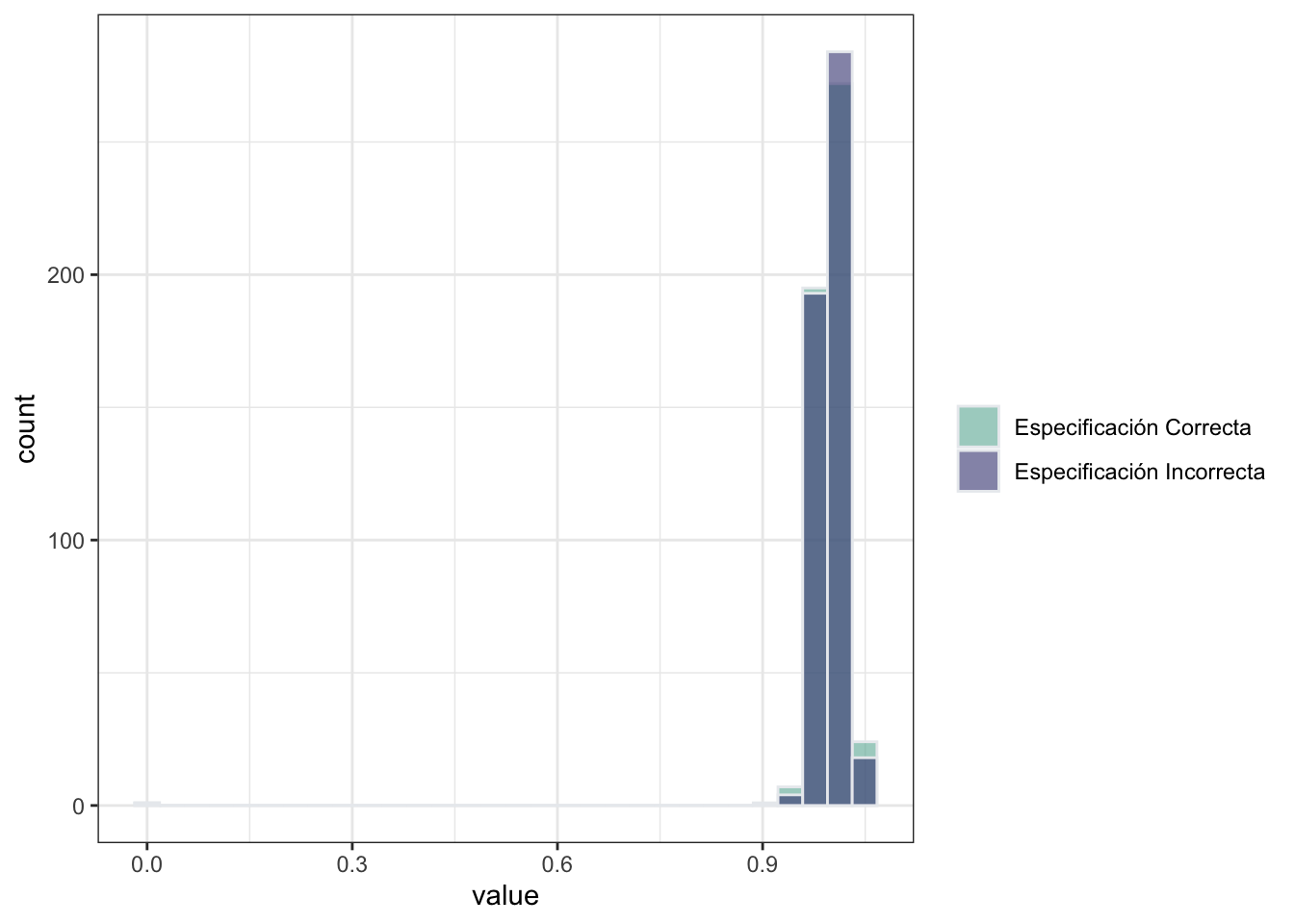
Ahora bien, el hecho de que el efecto marginal promedio sea consistente, eso no quiere decir que lo sea cuando evaluamos en valores específicos de \(x\). Por ejemplo, la siguiente gráfica muestra la distribución del efecto marginal promedio cuando evaluamos en \(x=6\). Como resulta claro de esta gráfica, la distribución de efecto marginal promedio deja de ser consistente.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.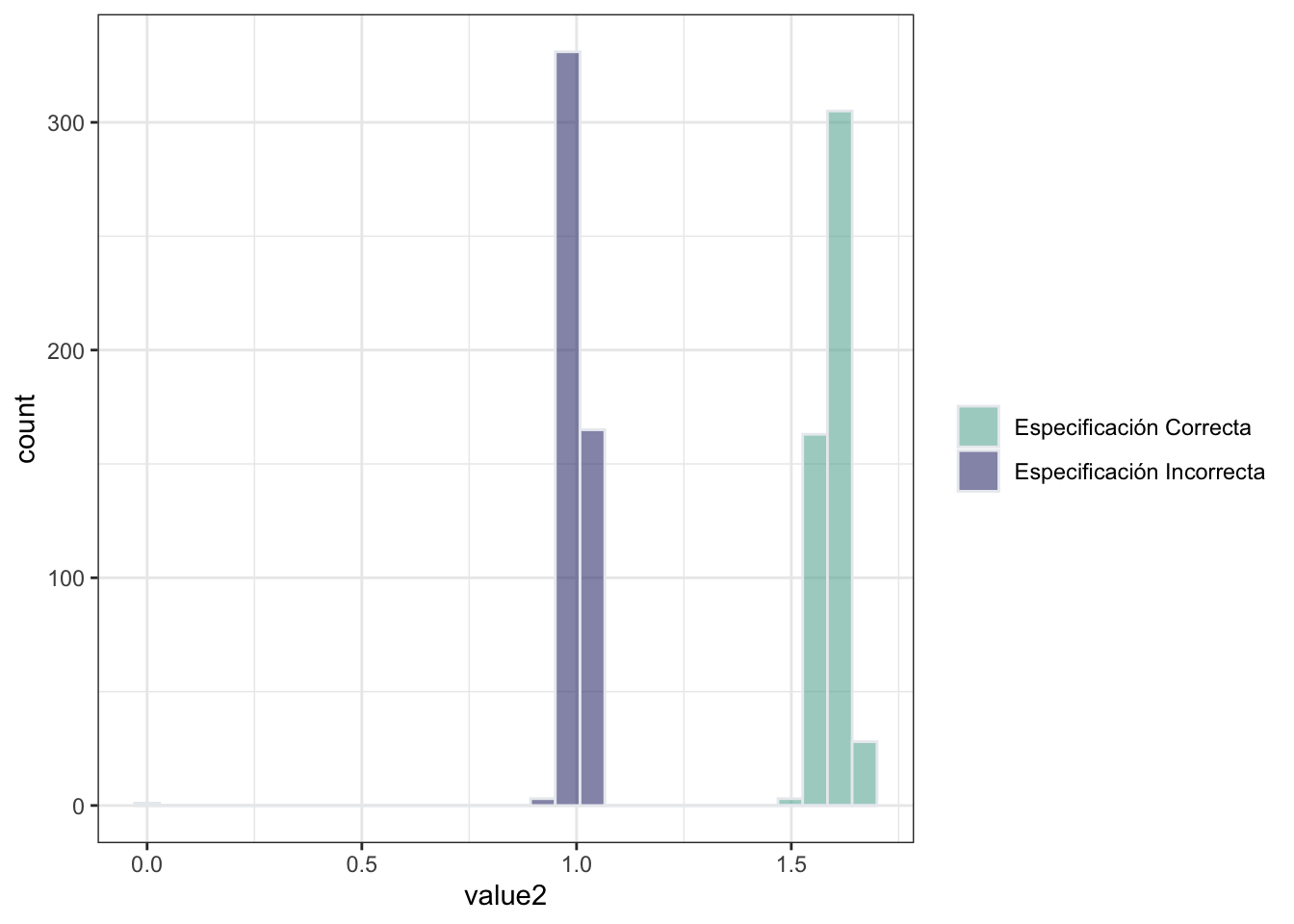
Finalmente, visualizamos el efecto marginal promedio de \(z\) sobre \(y\). En este caso, dado que la distribución de \(z\) está (por construcción) sesgada, vemos que la estimación del efecto marginal no es consistente.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.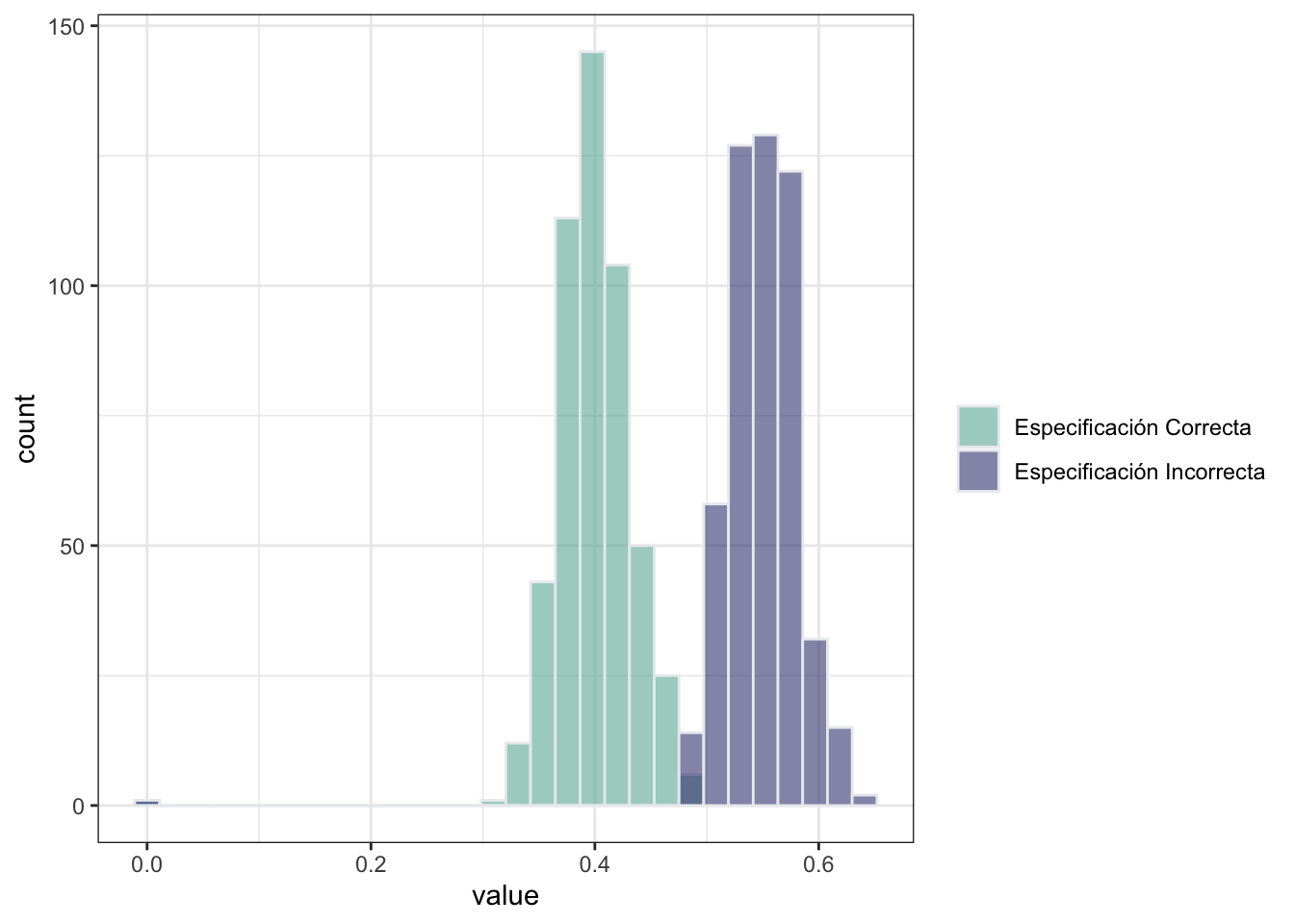
La moraleja es que, a menos que la distribición que siguen los datos sea simétrica, una especificación incorrecta del modelo (aun en casos tan simples como dejar fuera a un elemento cuadrático) conducirá a estimaciones inconsistentes.
Residuales de un modelo mal especificado
Cuando un modelo está bien especificado, los residuales de la regresión no tienen un comportamiento identificable. Más bien, tienen un comportamiento que es errático e impredecible y oscilan alrededor de cero. Para ver qué pasa cuando el modelo está mal especificado, generaremos datos artificiales y correremos tres modelos, dos de ellos mal especificados.
### Define variables
nobs <- 10000
x <- runif(nobs, min=0, max=1)
z <- runif(nobs, min=0, max=1)
u <- rnorm(nobs,0,1)
y1 <- 0 + 1*x + 5*z + u
y2 <- 0 + 10*x^2 + 2*z + u
y3 <- exp(-1 + 1*x + 3*z + u)
### Run regressions
mod1 <- lm(y1~x+z) # Modelo bien especificado
mod2 <- lm(y2~x+z) # Modelo mal especificado
mod3 <- lm(y3~x+z) # Modelo mal especificado
### Residual plots
plot(mod1, which=1, col=c("blue"))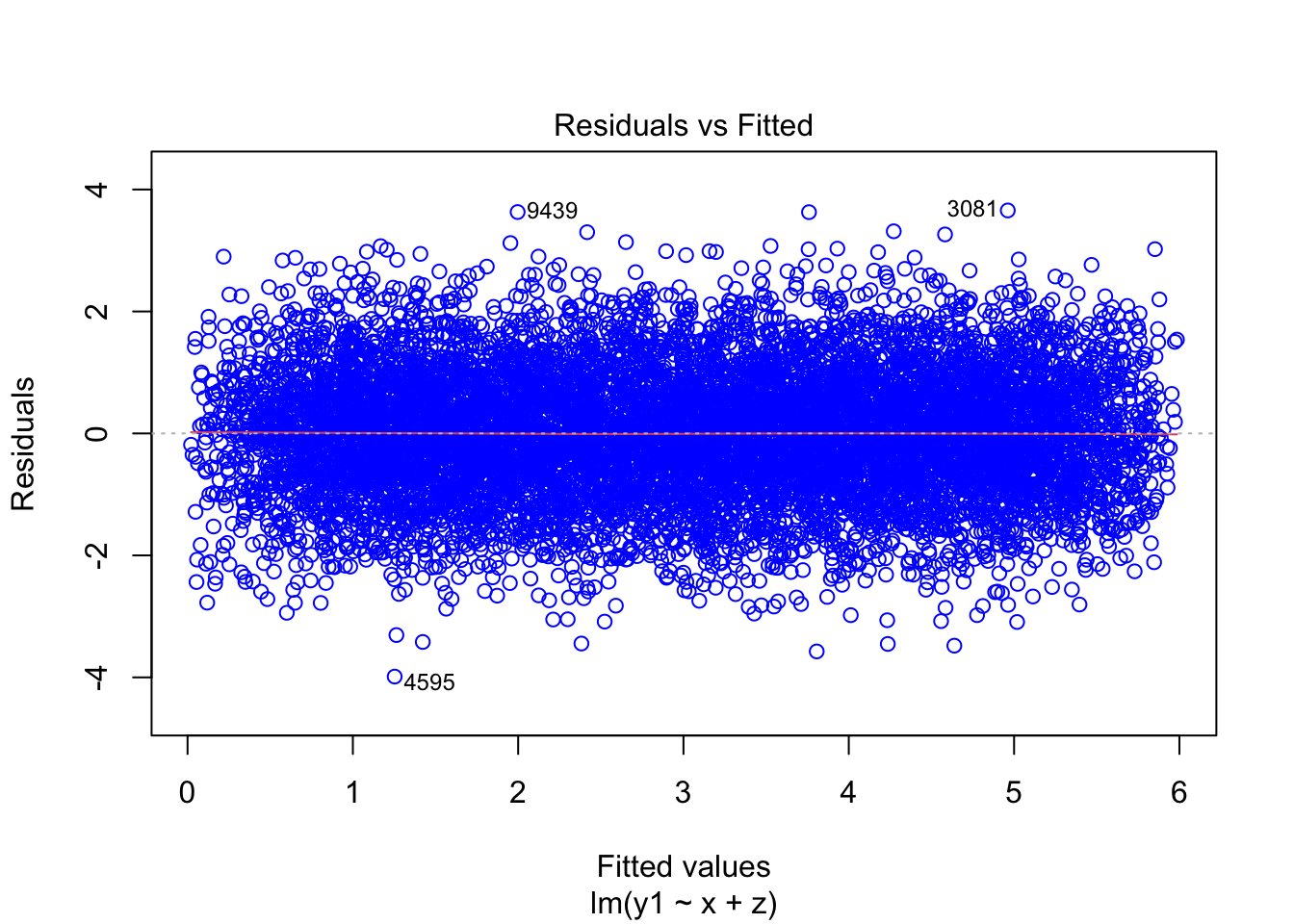
plot(mod2, which=1, col=c("blue"))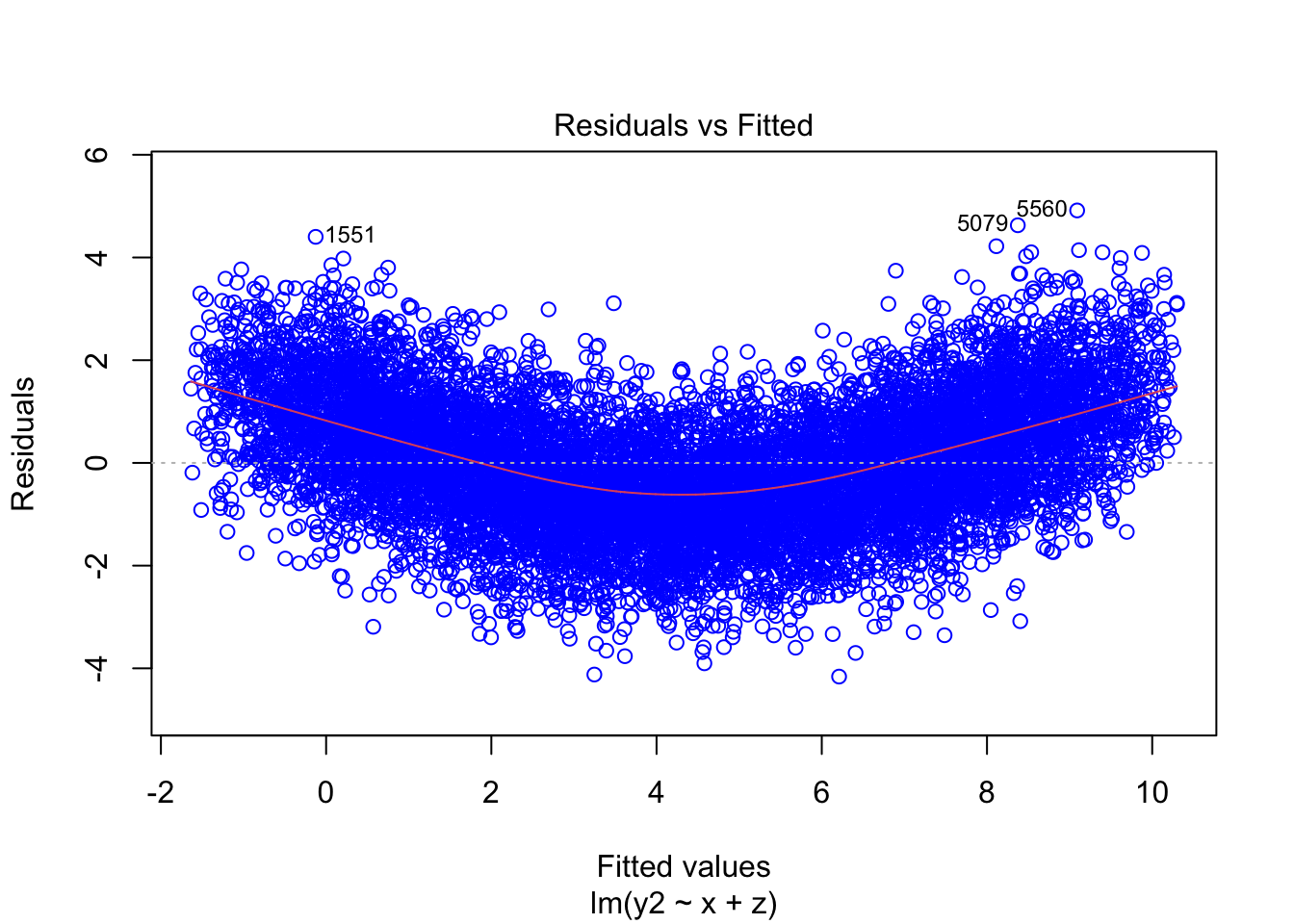
plot(mod3, which=1, col=c("blue"))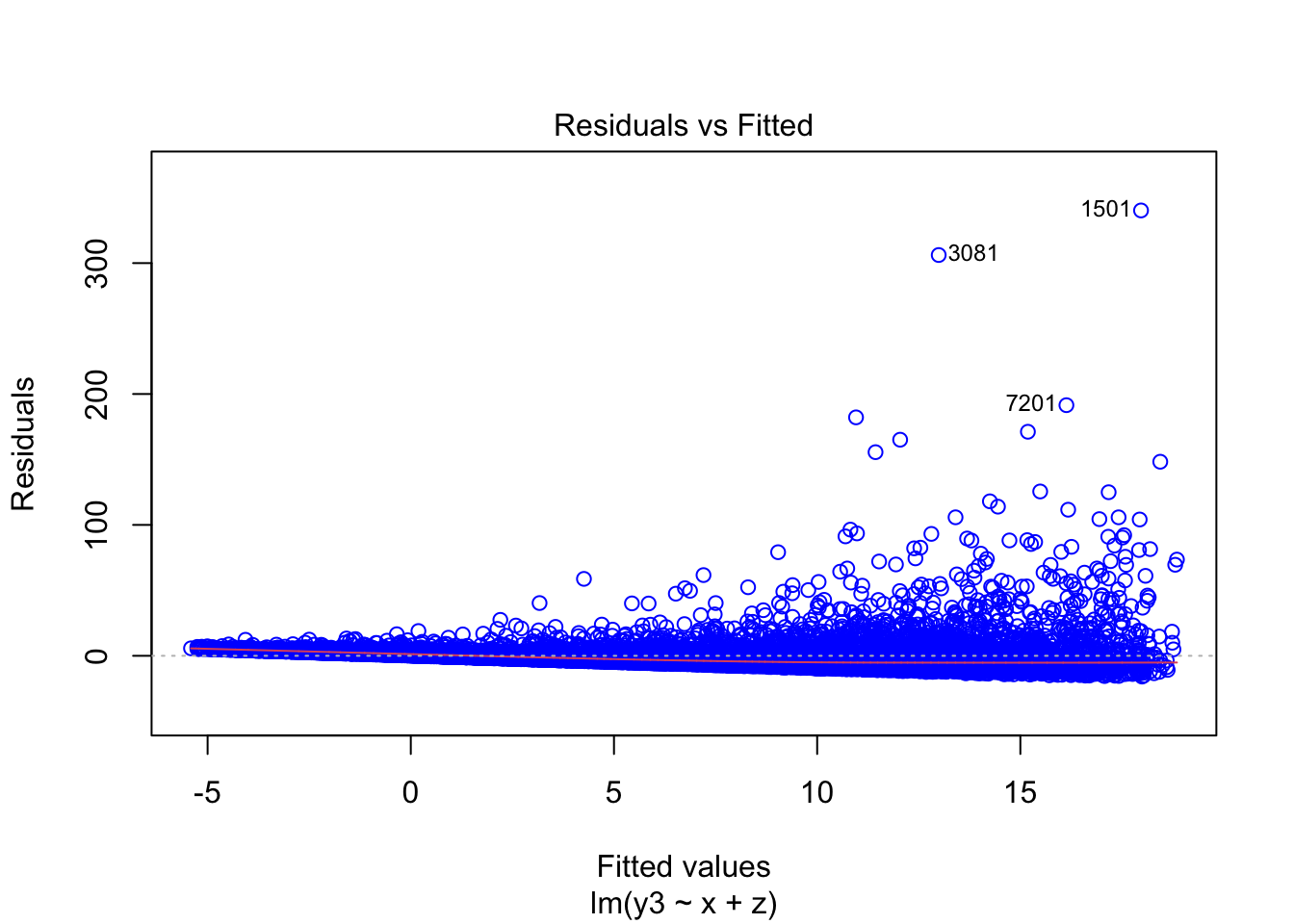 Como puede observarse, cuando el modelo está bien especificado, efectivamente tenemos residuales que oscilan alrededor de cero y cuyo comportamiento es errático, es decir impronosticable. Sin embargo, cuando el modelo está mal especificado, el comportamiento de los errores puede predecirse. Por ejemplo, vemos que los residuales del segundo modelo tienen un comportamiento en forma de U. En el tercer modelo, se aprecia que los residuales tienen una tendecia decreciente.
Como puede observarse, cuando el modelo está bien especificado, efectivamente tenemos residuales que oscilan alrededor de cero y cuyo comportamiento es errático, es decir impronosticable. Sin embargo, cuando el modelo está mal especificado, el comportamiento de los errores puede predecirse. Por ejemplo, vemos que los residuales del segundo modelo tienen un comportamiento en forma de U. En el tercer modelo, se aprecia que los residuales tienen una tendecia decreciente.
Prueba de especificación
Una de las pruebas de especificación más conocidas es la prueba RESET de Ramsey. Supongamos que el modelo al cual deseamos aplicar la prueba es:
\[ y_i = \beta_1 + \beta_2 x_{i2} +u_i \] Para realizar la prueba seguimos los siguientes pasos:
- Correr el modelo por MCO y guardar los valores ajustados, \(\widehat{y}_i\).
- Correr por MCO el siguiente modelo: \[ y_i= \delta_1 + \delta_2 x_{i2} + \delta_3 \widehat{y}_i^2 + \delta_4 \widehat{y}_i^3+u_i \]
- Realizamos una prueba F para verificar la significatividad conjunta de \(\widehat{y}_i^2\) y \(\widehat{y}_i^3\) (y los demás términos polinómicos que agreguemos). Si la hipótesis \(H_0: \delta_3=\delta_4=0\) no se rechaza, entonces el modelo de base está bien especificado.
Apliquemos la prueba RESET a los tres modelos analizados en la sección anterior.
resettest(mod1, power=2:3, type="fitted")##
## RESET test
##
## data: mod1
## RESET = 0.0012509, df1 = 2, df2 = 9995, p-value = 0.9987resettest(mod2, power=2:3, type="fitted")##
## RESET test
##
## data: mod2
## RESET = 2112, df1 = 2, df2 = 9995, p-value < 2.2e-16resettest(mod3, power=2:3, type="fitted")##
## RESET test
##
## data: mod3
## RESET = 235.97, df1 = 2, df2 = 9995, p-value < 2.2e-16Observa los valores p de la prueba RESET. Cuando el valor p<10%, rechazamos \(H_0\), lo cual sería un indicativo de una especificación incorrecta del modelo analizado.
Última actualización: 29-07-2020.