
El modelo de regresión lineal
En general, el modelo de regresión lineal toma la forma:
\[ y_i = \beta_1 + \beta_2 x_2 + \beta_3 x_3 + \dots + \beta_k x_k + u_i \]
La variable \(y_i\) es la dependiente y es la variable que deseamos aproximar. Las variables \(x_1, x_2,\dots, x_k\) son las explicativas (o independientes). El término \(u_i\) es un error, o ruido. Este implica que los coeficientes \(\beta_1, \beta_2 \dots, \beta_k\) sean desconocidos, por lo que tienen que estimarse. Para hacer esto utilizaremos el método de los mínimos cuadrados ordinarios.
En este post estaremos utilizando los siguientes paquetes de R:
# Instalar paquetes si es necesario
# install.packages("tidyverse")
# Leer paquetes
library(tidyverse)## ── Attaching packages ────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.1 ✓ dplyr 1.0.0
## ✓ tidyr 1.1.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ───────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(effects)## Warning: package 'effects' was built under R version 4.0.2## Loading required package: carData## lattice theme set by effectsTheme()
## See ?effectsTheme for details.Ahora, estamos listos para ver un ejemplo. Consideremos una muestra del Medical Expenditure Panel Survey 2004 de los Estados Unidos. Tómate un tiempo para analizar la base de datos, así como para realizar un análisis de estadística descriptiva.
db <- read_csv("https://raw.githubusercontent.com/amosino/courses--econometria/master/econometria_salud/econometria_salud--datos/MEPSData.csv")## Parsed with column specification:
## cols(
## .default = col_double(),
## famidyr = col_character(),
## hieuidx = col_character(),
## female = col_character(),
## race_bl = col_character(),
## race_oth = col_character(),
## eth_hisp = col_character(),
## ed_hs = col_character(),
## ed_hsplus = col_character(),
## ed_col = col_character(),
## reg_midw = col_character(),
## reg_south = col_character(),
## reg_west = col_character(),
## anylim = col_character(),
## ins_mcare = col_character(),
## ins_mcaid = col_character(),
## ins_unins = col_character(),
## ins_dent = col_character()
## )## See spec(...) for full column specifications.Deseamos modelar la dependencia que existe entre los gastos totales en salud (exp_tot), los cuales juegan el papel de la variable dependiente, en función de la edad de la persona (age) y del ingreso familiar en logaritmos (lninc). La función que nos permite estimar un modelo de regresión lineal usando mínimos cuadrados ordinarios es lm. Esta función tiene varios argumentos, pero los más importantes son formula, que representa al modelo en sí, y data, que es el objeto que contiene la base de datos. Otro argumento que en ocasiones podría ser importante es subset, el cual nos permite considerar solo un subconjunto de la muestra. En nuestro caso, no consideraremos a las personas cuyos gastos en salud hayan sido cero.
El resultado de la función lm es un objeto, al cual llamaremos mod1. Además, crearemos un segundo objeto, smod1, que almacenará la información de mod1 en una forma más completa y más parecida a la que nos arrojan la mayoría de los paquetes econométricos.
mod1 <- lm(exp_tot~age+lninc, data=db, subset=(exp_tot>0))
smod1 <- summary(mod1)
print(smod1)##
## Call:
## lm(formula = exp_tot ~ age + lninc, data = db, subset = (exp_tot >
## 0))
##
## Residuals:
## Min 1Q Median 3Q Max
## -12125 -3629 -1970 136 437153
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5376.715 1020.447 5.269 1.39e-07 ***
## age 119.088 4.738 25.133 < 2e-16 ***
## lninc -612.811 89.255 -6.866 6.86e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10360 on 15943 degrees of freedom
## Multiple R-squared: 0.04571, Adjusted R-squared: 0.04559
## F-statistic: 381.9 on 2 and 15943 DF, p-value: < 2.2e-16Bastante simple, ¿no es así?
De la tabla anterior podemos ver, por ejemplo, que cada año adicional de vida aumenta en promedio los gastos en salud en 119.088 dólares anuales, mientras que un incremento en el ingreso familiar los reducen. Naturalmente que la especificación que hemos considerado es bastante pobre, lo cual queda de manifiesto en el valor de la \(R^2\), que es igual a 0.045. En otras palabras, las variables que hemos incluido solo son capaces de explicar el 4.5% de la variabilidad en los gastos en salud. Más adelante mejoraremos un poco la especificación, pero antes veámos otros comandos que pueden ser útiles para visualizar los resultados de un modelo de regresión. Los primeros son las funciones effect y allEffects de la librería effects. Estas nos muestran gráficamente el efecto marginal de una o todas las variables del modelo, respectivamente. El efecto marginal no es más que la derivada parcial de \(y\) con respecto a alguna variable explicativa \(x_k\). En nuestro ejemplo estos efectos marginales son constantes e iguales a \(\beta_2\) y \(\beta_3\). Por esta razón, las gráficas que obtenemos son líneas rectas. Por ejemplo, vemos que conforme una persona envejece, el gasto total en salud esperado crece a una tasa constante.
plot(effect("age", mod1))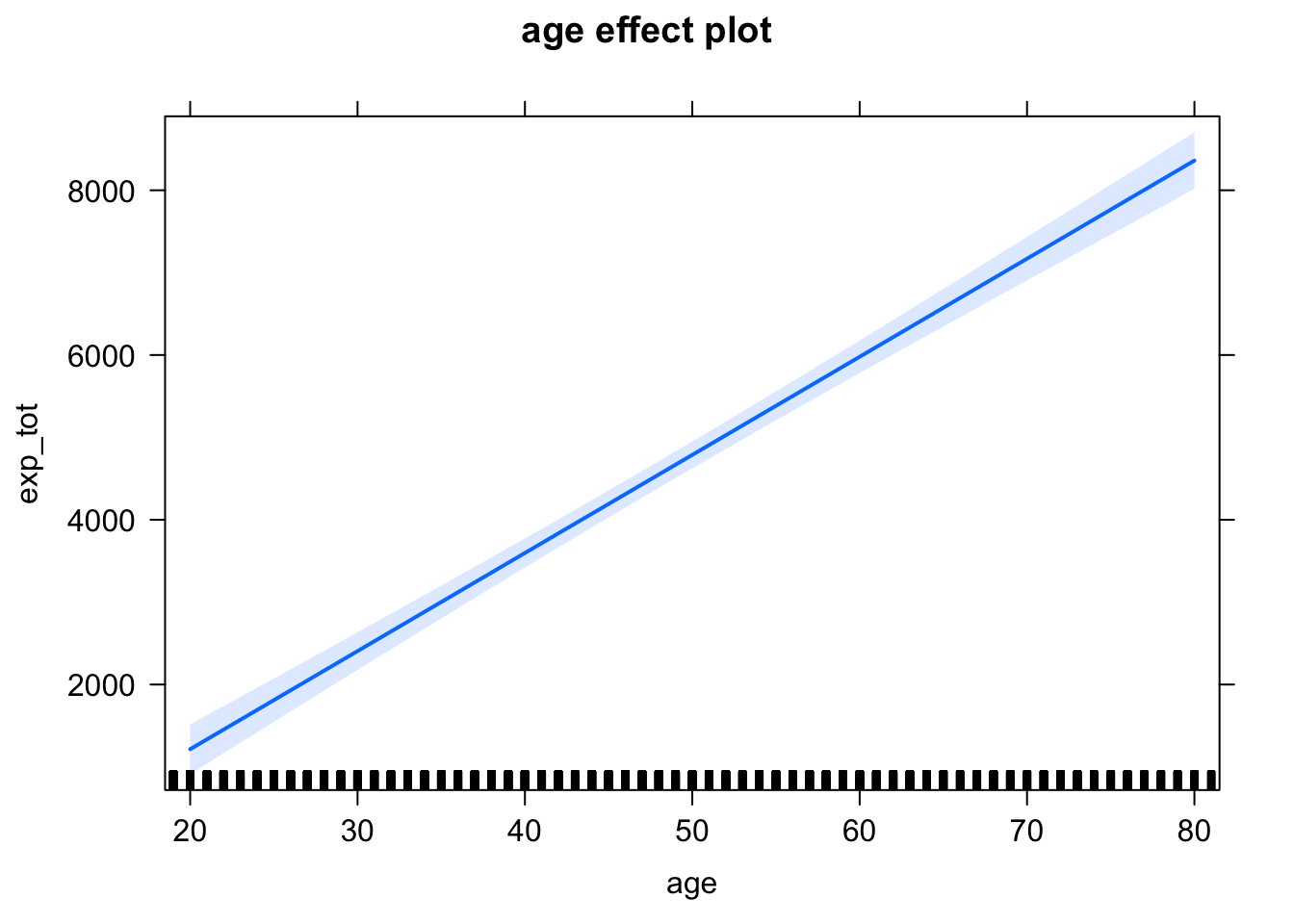
plot(allEffects(mod1))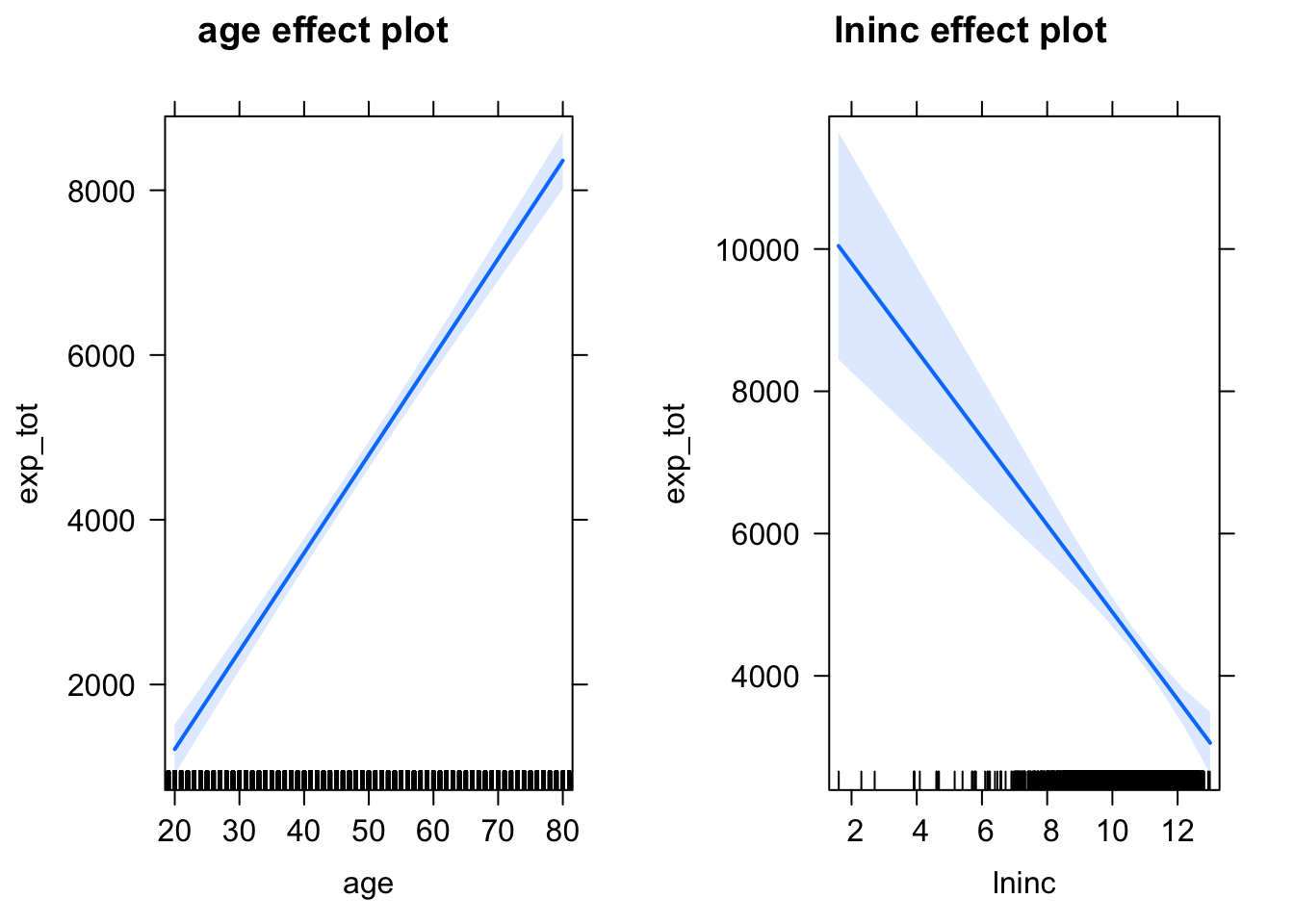
Naturalmente, los efectos de una variable no siempre crecen o decrecen a tasas constantes. Por ejemplo, incluyamos en el modelo al cuadrado de la edad como una variable explicativa adicional. El supuesto implícito es precisamente que el efecto de la edad sobre el gasto podría no ser una constante. Nota la forma en que se modifica la fórmula en la función lm. Queda como ejercicio que el lector realice el ejercicio de primero agregar el cuadrado de la edad en la base de datos y luego incluir esta nueva variable en la función lm. ¿Cuál es la diferencia?
mod2 <- lm(exp_tot~age+I(age^2)+lninc, data=db, subset=(exp_tot>0))
smod2 <- summary(mod2)
print(smod2)##
## Call:
## lm(formula = exp_tot ~ age + I(age^2) + lninc, data = db, subset = (exp_tot >
## 0))
##
## Residuals:
## Min 1Q Median 3Q Max
## -12406 -3420 -1971 26 437231
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6967.637 1089.801 6.393 1.67e-10 ***
## age 14.604 25.656 0.569 0.569
## I(age^2) 1.052 0.254 4.144 3.44e-05 ***
## lninc -549.934 90.492 -6.077 1.25e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10350 on 15942 degrees of freedom
## Multiple R-squared: 0.04674, Adjusted R-squared: 0.04656
## F-statistic: 260.6 on 3 and 15942 DF, p-value: < 2.2e-16plot(effect("I(age^2)", mod2))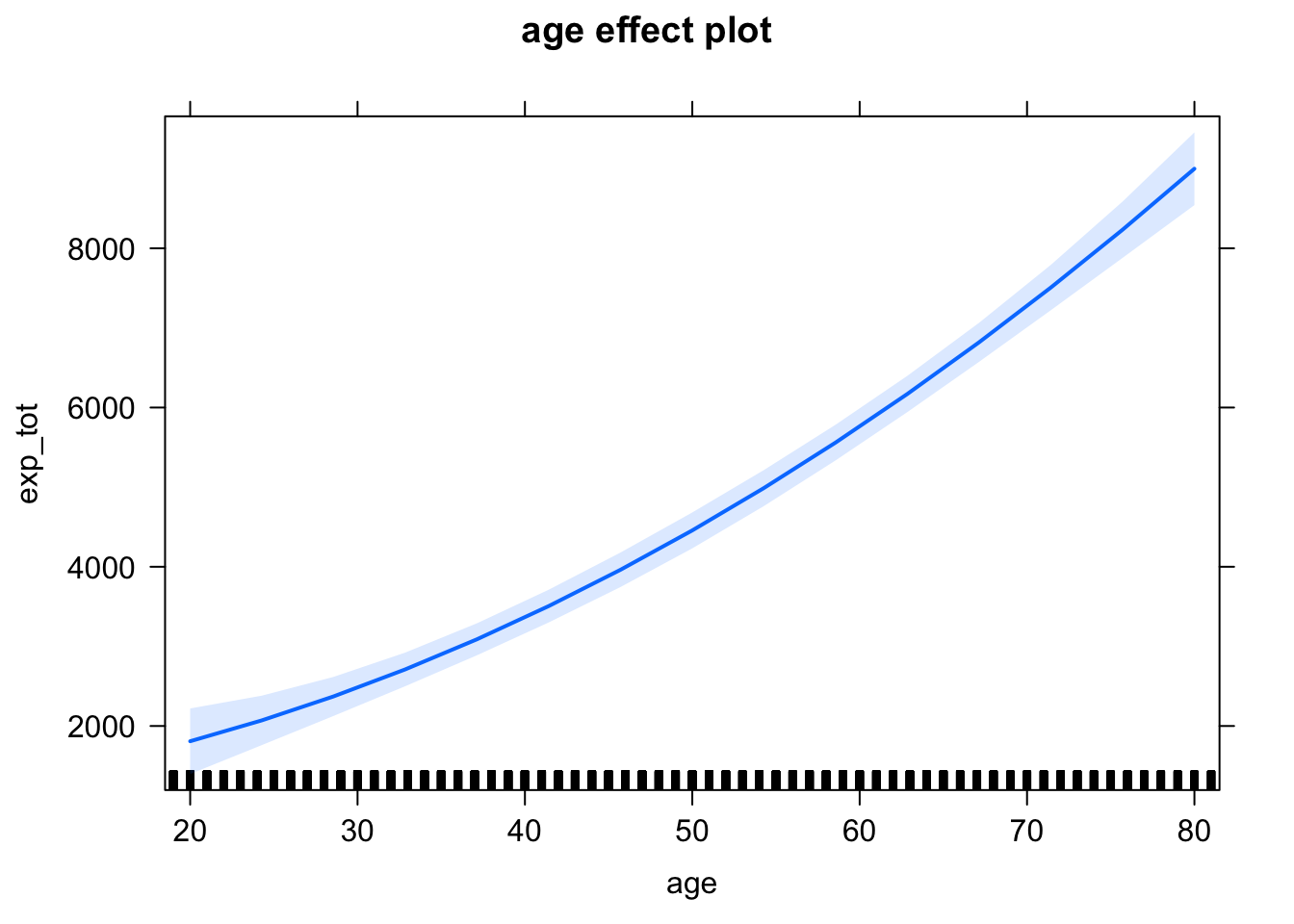
Con esta modificación al modelo, el efecto marginal de la variable age sigue siendo creciente, pero no es constante. Más bien, la gráfica indica que los gastos en salud aumentan más rápido conforme las personas van envejeciendo. Esto se debe al signo positivo del coeficiente del cuadrado de la edad (I(age^2)). Puesto simple, los datos indican que el aumento en gastos no es igual cuando se tienen 20 años y se cumplen 21, que cuando se tienen 80 y se cumplen más. Suena lógico, ¿no te parece?
Finalmente, es importante destacar que gran parte de la información que aparece en las tablas de resultados podría ser útil para hacer cálculos posteriores (si bien R nos permite automatizar muchos de estos). Por ejemplo, ¿cuál sería el gasto en salud promedio para una persona con 45 años y un ingreso familiar en logaritmos de 10 (equivalente a un ingreso de aproximadamente 22000 dólares anuales)? Para hacer esto, podríamos utilizar los resultados del modelo estimado. Guardemos el resultado de nuestra operación en un objeto (en este caso, un escalar) que llamaremos exp_tot1:
exp_tot1 <- coef(mod2)[[1]] + coef(mod2)[[2]]*45 + coef(mod2)[[3]]*45^2 + coef(mod2)[[4]]*10
print(exp_tot1)## [1] 4256.72¿Te hace sentido? Simplemente estamos utilizando los valores de la edad y el ingreso seleccionados en conjunto con los coeficientes del modelo 2. Estos últimos se extraen con la función coef(), de tal forma que coef(mod2)[[1]] es el primer coeficiente del modelo 2, coef(mod2)[[2]] es el segundo coeficiente del modelo 2, y así sucesivamente.
Otros ejemplos de valores que podemos extraer de los resultados de una regresión son:
df <- mod2$df.residual # Grados de libertad
N <- nobs(mod2) # Número de observaciones
coefs <- coef(mod2) # Coeficientes estimados
sigh <- smod2$sigma^2 # Varianza del error
anov <- anova(mod2) # Análisis de varianza
vcm <- vcov(mod2) # Matriz de covarianzas Cuando tenemos vectores o matrices, como el vector de coeficientes, la anova o la matriz de covarianzas, podemos aun extraer información puntual utilizando índices.
b1 <- coefs[[1]] # Coeficiente de beta 1
b2 <- coefs[[2]] # Coeficiente de beta 2
b3 <- coefs[[3]] # Coeficiente de beta 3
b4 <- coefs[[4]] # Coeficiente de beta 4
RSS <- anov[3,2] # Suma del cuadrado de los residuales
TSS <- sum(anov[,2]) # Suma de cuadrados totales
ESS <- TSS-RSS # Suma de cuadrados de la regresión
varb1 <- vcm[1,1] # Varianza de b1
varb2 <- vcm[2,2] # Varianza de b2
varb3 <- vcm[3,3] # Varianza de b3
covb1b2 <- vcm[1,2] # Covarianza de b1 y b2
covb1b3 <- vcm[1,3] # Covarianza de b1 y b3
covb2b3 <- vcm[2,3] # Covarianza de b2 y b3
seb2 <- sqrt(varb2) # Error estándar de b2
seb3 <- sqrt(varb3) # Error estándar de b3Última actualización: 26-07-2020.